
Bots and crawlers are automated programs that browse the internet, often visiting websites in order to index them for search engines. While this can be helpful for bringing traffic to your site, it can also be harmful if there is too much unwanted traffic. Unwanted traffic can slow down your website, clog up your server, and even crash your site. In order to prevent this, it is crucial to take measures to keep certain types of bots and crawlers from crawling your site.
If you are asking yourself “how to stop bots from crawling my website?”, you came to the right place.
One way to do this is to use a robots.txt file to tell crawlers which pages to avoid. You can also use code on your web pages to deter bots and crawlers from visiting them. Taking these measures can help keep your site running smoothly and prevent it from being overwhelmed by unwanted traffic.
What does “Bot” mean?
A bot is an automated program that browses the internet and performs tasks, often visiting websites in order to gather information or perform actions.
Why should you prevent certain bots from crawling your site?
Preventing certain bots from crawling your site can help to keep your server from becoming overwhelmed by unwanted traffic, potentially crashing your website. It can also protect sensitive information on your site from being accessed by unauthorized bots.
Bots and Crawlers Will Take Up Too Much Bandwidth
Bots and crawlers will take up too much bandwidth and slow down your website, or even crash it and make it inaccessible for some time. Also, malicious bots can potentially access sensitive information on your website. By controlling which bots can crawl your site, you can prevent these negative consequences.
Controlling the Malicious Bot Attacks Beforehand
Preventing certain bots from crawling your site can also help to protect against malicious bot attacks, such as spamming your website with fake comments or attempting to gain access to private information.
Malicious bots can be a serious problem for website owners. By bombarding a site with requests, they can quickly overload the server and cause the site to crash. They can also scrap content, steal personal information, and generate fake traffic in order to inflate advertising revenue. So, it’s important to take steps to control and limit malicious bots and crawlers before they become a problem.
Preventing Data Breaches
Another reason to prevent certain bots from crawling your site is to protect sensitive information and prevent data breaches. Bots can potentially access private customer or business information, so keeping certain types of bots out of your website can help to keep this information secure.
Best ways to Block Bots from Crawling your Site
There are a few different ways that you can block bots from your website. The first is through the use of a robots.txt file. This is a file that sits on the root of your web server and tells bots which areas of your site they are allowed to access. By default, you may not have a robots.txt file, so you would need to create one. There are a few different codes that you can use in your robots.txt file to block bots effectively.
Blocking All Kinds of Bots
User-agent: *
Disallow: /
If you want to keep your site private or launch it at a later date, this is the code you will want to use.
This will keep your site hidden from all kinds of bots and crawlers, including Google bots.
Blocking Google’s Bots/Crawlers Googlebot
Googlebot is the name of Google’s web crawler.
If you want to prevent Googlebot from crawling your website, you can add the following code to your robots.txt file:
User-agent: Googlebot
Disallow: /
This code will tell Googlebot not to crawl any pages on your site.
However, you should only use this code if you have a specific reason for wanting to prevent your site from being indexed by Google.
For example, if you have a staging site that you don’t want to be indexed, you can use this code to prevent Googlebot from crawling it.
Otherwise, you may end up with duplicate content issues on your site.
Blocking Bing’s Crawler Bingbot
If you want to block Bing’s bot Bingbot from crawling your website, you’ll have to add the following code to your robots.txt file:
User-agent: Bingbot
Disallow: /
Blocking Yahoo’s Crawler Slurp
If you want to prevent Yahoo’s crawler (known as Slurp) from crawling your site, you can use the following code in your robots.txt file:
User-agent: Slurp
Disallow: /
You can also use this same code to block any other search engine’s crawler, by simply replacing “Slurp” with the name of the crawler.
It’s important to note that blocking a search engine’s crawler will also prevent your site from appearing in that search engine’s search results.
So, it should only be used if you have a specific reason for wanting to do so.
Blocking SEO Tools’ Spiders and Crawlers
SEO professionals often use common SEO Tools like Semrush and Ahfres to assess their competition, and these tools use bots, crawlers, and spiders to get that information.
This might be the main reason why you might want to block Spiders and Crawlers that belong to Ahrefs or Semrush, but there are other reasons why you would want to block these bots from crawling your site. For example, these crawlers are not exactly like google’s bots. Semrush or Ahrefs bots can slow down your page A LOT if someone starts a crawl for your website, and they can also consume a lot of bandwidth.
In addition, some bots can create false traffic on your GA(Google Analytics), which can skewer results when trying to determine the popularity of a site.
As a result, many SEO professionals choose to utilize robots.txt to block common bots that they use to assess their competition. This helps to ensure that they are able to accurately assess their website’s traffic and improve their chances of ranking highly in search engine results pages.
Semrush
Here are the lines of codes you need to add to your robots.txt to block Semrush Crawler from your website.
Be careful! There are so many lines of code, add these to your robots.txt carefully!
To block SemrushBot from crawling your site for the On-Page SEO Checker tool and similar tools:
User-agent: SemrushBot-SI
Disallow: /
To block SemrushBot from crawling your site for different SEO and technical issues:
User-agent: SiteAuditBot
Disallow: /
To block SemrushBot from crawling your site for the Backlink Audit tool:
User-agent: SemrushBot-BA
Disallow: /
To block SemrushBot-COUB from crawling your site for the Content Outline Builder tool:
User-agent: SemrushBot-COUB
Disallow: /
To block SemrushBot from crawling your site for Content Analyzer and Post Tracking tools:
User-agent: SemrushBot-CT
Disallow: /
To block SemrushBot from crawling your site for Brand Monitoring:
User-agent: SemrushBot-BM
Disallow: /
To block SemrushBot from checking URLs on your site for the SWA tool:
User-agent: SemrushBot-SWA
Disallow: /
Ahrefs
Here are the lines of codes you need to add to your robots.txt for blocking AhrefsBot from your website.
With this code, you can specify the minimum acceptable delay between two consecutive requests from AhrefsBot. This won’t block the crawler but limit its request frequency so it doesn’t tank your website’s bandwidth.
User-agent: AhrefsBot
Crawl-Delay:
To block the AhrefsBot from crawling your website completely add this code to your robots.txt file:
User-agent: AhrefsBot
Disallow: /
Blocking Bots from Crawling a Specific Folder
To prevent the bots from crawling a certain folder on your website, add this piece of code to your robots.txt file.
User-agent: *
Disallow: /folder-name/
Common Mistakes with Robots.Txt
There are several serious mistakes that website owners and SEO Specialists make when editing their robots.txt files.
Not Including the Full and Correct Path
It is important to include the full path in your robots.txt file, otherwise, it won’t work properly.
For example, if you want to block crawlers from accessing a specific page on your website, the code should be:
Disallow: /path/to/specific-page.html
Using Both Noindex in Robots.txt and Disallow On the Page
When it comes to indexing pages on your website, Google gives you a few different options. You can use the robots.txt file to prevent Google from crawling certain pages, or you can add a no-index tag to individual pages.
However, according to John Mueller of Google, you should not use both methods at the same time. If you use the disallow command in robots.txt, Google will not be able to crawl the page and see the no-index tag. As a result, the page could still be indexed, even though you are trying to prevent it.
For this reason, Mueller recommends using only one method or the other, but not both. By carefully choosing how you index your pages, you can help ensure that only the most relevant and useful information is being made available to your users.
Not Testing Your Robots.Txt File
After making changes to your robots.txt file, it is important to test it before assuming that it will work properly.
This can be easily done by using Google’s robots.txt tester tool or using a crawler simulator such as Screaming Frog’s SEO Spider tool. These tools will allow you to see if there are any errors in your robots.txt file and if any pages are being blocked incorrectly.
How to Analyze Bot Activities on a Site – Log File Analysis
Log file analysis is a technical SEO task that lets you see exactly how Googlebot (and other web crawlers and users) interacts with your website.
A log file gives you valuable insights that can inform your SEO strategy or solve problems surrounding the crawling and indexing of your web pages. By analyzing log files, you can see how often Googlebot (and other crawlers) visits your site, which pages it crawls, and any errors that it encounters.
You can also see which users visit your site and how they interact with your content. This data can be extremely valuable in understanding how Google views your site and what changes you need to make to improve your ranking.
If you’re not already doing log file analysis, it’s time to start!
How to Start Doing Log File Analysis
When you have access to a log file, you can start analyzing them in the following ways:
- Excel or other data visualization tools
- Using the log file analysis tools
JetOctopus
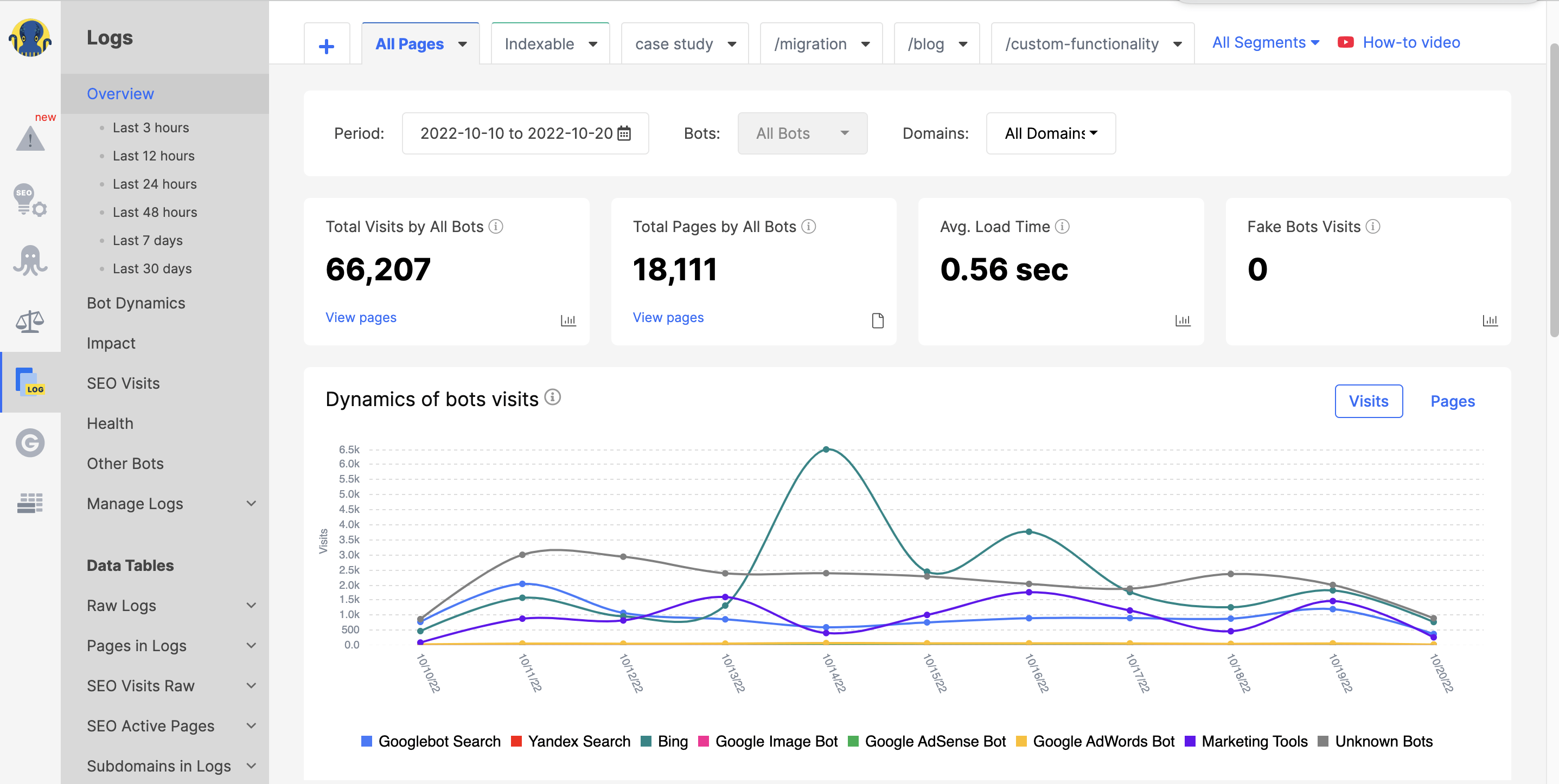
While there are a number of different log analyzer tools on the market, JetOctopus is widely considered to be the best in terms of affordability and features. For starters, the tool offers a seven-day free trial with no credit card required. This is ideal for those who want to try out the tool before committing to a paid subscription.
Additionally, JetOctopus boasts a two-click connection, making it one of the most user-friendly options on the market. With this tool, you’ll be able to quickly and easily identify crawl frequency, crawl budget, most popular pages, and more.
What’s more, JetOctopus allows you to integrate log file data with Google Search Console data. This gives you a distinct advantage over the competition as you’ll be able to see how Googlebot interacts with your site and where you may need to make improvements.
Ultimately, if you’re looking for an affordable and feature-rich log analyzer tool, JetOctopus is the way to go.
Screaming Frog Log File Analyzer

The Screaming Frog log file analyzer tool is also an amazing choice. Its features include the ability to crawl websites and collect data on them, including metadata, internal and external links, and images.
The free version allows for a single project with a limit of 1000 line log events. You’ll need to upgrade to the paid version if you want unlimited access and technical support.
The paid version also gives you additional features, such as the ability to fetch Google Analytics data and technical support. If you manage multiple websites, the Screaming Frog tool is an invaluable asset.
You can also do the following:
- Search engine optimization statistics and search engine bot activity.
- Find out how frequently search engine bots visit your website.
- Learn about all of the technical SEO difficulties and broken links on the website.
- Analysis of the most and least crawled URLs to boost efficiency and decrease loss.
- Find pages that search engines aren’t currently crawling.
- Any data, including data from other links, instructions, and other information, can be compared and combined.
- View the referrer URL information
SEMrush Log File Analyzer

For anyone looking for a simple, browser-based log analysis tool, the SEMrush Log File Analyzer is a great choice.
There’s no need to download anything – you can use the online version. SEMrush provides two reports: Pages’ Hits and The activity of the Googlebot.
Pages’ Hits gives you data on pages, folders, and URLs with maximum and minimum interactions with bots.
The Googlebot Activity report provides site-related insights on a daily basis, including information on crawled files, HTTP status codes, and requests made by various bots. Whether you’re just starting out or have years of experience, this analyzer can be a valuable addition to your toolkit.
Conclusion
Overall, keeping track of who and what crawls and indexes your website and doing proper log file analysis is a crucial component of understanding what changes you need to make in order to improve your rankings. With the right help and tools, you’ll be able to identify and address any technical SEO issues and boost your site’s performance. Also, don’t be shy, ask us about any issues you have with your website’s SEO and our team of SEO experts will do their best to help you fix and improve your SEO for the better.


