

When developing a software application, one of the most common problems is distinguishing between the development, test, and production environments, which consequently duplicates the database instances of a software product, and any change on one breaks the consistency with others.
The file changes can be tracked with Version Controlling Software.
Outdated Architecture Patterns
We often see organizations use outdated architecture patterns when developing a database.
These can slow down developers and limit user acceptance testing, which is why it’s so important that they’re updated!
It’s time to upgrade these database environments and improve standards for database development.
In combination, the requirement results in a more complex and difficult environment than is used in the production environment- which leads us to some tricky problems when it comes down to actually using said databases on our end!
The most common challenge in these environments is the lack of up-to-date data.
They are often perfect for development or testing purposes, so you can get your idea out there without having constraints on what kind of information might be available to work with!
This creates a bottleneck because the databases need to be refreshed in order for developers’ work to continue smoothly.
This can lead them outside of office hours and slow down development progress, requiring IT staff who are already busy with day-to-day projects likewise working overtime on these extra requests while they finish their data updates as quickly as possible!
Transactional Replication in Production
The need for a more efficient way to manage this type of database has become clear with transactionally replicated production data.
The problem is that it’s often much closer in proximity and cohesion with the software development process than just’ availability groups’.
Capturing the schema for replicated tables in source control can help you automate their implementation and management across development, test environments.
This could be time-consuming so it’s important to consider whether this approach leads long term towards efficiency or improvement of quality?
The key question is whether it’s a good idea to emulate low-availability traits in a production environment.
Best Practices for Development and Test Data Environment Architecture
1-) Critical Databases Must Have At Least One Staging Environment
This environment is perfect for performance testing and any other type of test which requires a “production-like” implementation.
Some tips on how to keep your staging environment production-like:
Automate refresh/reset of the system as much as possible; monitor it with all monitoring tools in place and make sure there are no alerts before rolling out any changes or updates that could affect production.
If you’re updating code, then update only those parts which have been manually checked for compatibility by QA – this will help avoid introducing regressions into an already unstable customer experience if something goes wrong during the testing phase!
When launching new features onto live systems take note about what data was being used beforehand so they can’t catch unaware when developers start scraping sensitive info from logs without realizing.
2-) Development and Test Environments Should Be Ephemeral
The ability to quickly generate development and test environments on-demand is important for the rapid iteration cycles that are key in21st century technology.
Automation tools such as Pull Requests can be used to make this process even faster!
3-) Safe Datasets Must Be Available For Development and Test Environments
Developing and testing environments should never contain Personally-Identifying Information or other sensitive data.
This is a risk to your business, as they are an attractive target for breaches!
One of the most important steps to preventing a data breach is sanitizing your database.
This ensures that any sensitive information it contains does not find its way into malicious hands and can only be accessed by authorized users within an organization who have been appropriately vetted for such access levels.
4-) Developers Must Have Full Control Over Development and Test Environments
This one is obvious for some organizations, but very scary indeed.
Developers need to have the highest level of permissions in order to extract and experiment with test data without any problem at all – they’re going into what could be another person’s personal life after all!
The developer’s permission should be high to prevent any problems that might arise.
With a technology that allows them easily recreate development environments, developers can work and create without worry of accidental errors since all data will always remain safe as long they have access for fixing the issues in case anything goes wrong with one person’s permissions or another before then.
When we allow failures in development and test environments, it’s not just OK but welcomed as an opportunity to learn from our mistakes.
Let’s now focus on two suggested techniques for tracking database changes.
Technique 1 – Version your database change scripts
This technique has also been suggested by Martin Fowler, software engineer and especially popular with Agile Software Development Methodologies, which you can learn more about on his blog page. These steps will help you logically apply this technique:
- When making any change to a database object, you must first save the change synchronization script (i.e. ALTER TABLE … script) to a file (.sql, .txt file etc.) and version that file in your Version Control repository with an identity for each script. Identity can be in time format or a series of chronological numbers.
- Keep the last executed change script in the database. For instance, create a Config (Key varchar, Value varchar) table and save “LastExecutedChangeScript” with the identity you specified for it.
- Include some checkpoints in your project. For instance, in Admin CP to ensure your database’s LastExecutedChangeScript is up to date according to the change script file. If not, execute the change scripts from
- LastExecutedChangeScript to the latest one, and update the corresponding database Config record.
- Change file should be updated automatically with the revision control system. Let the magic begin!

This approach is very straightforward and should be selected anytime if it is applicable.
However, if you are using third-party software like WordPress, you cannot track database changes because any plug-in, or even WordPress itself, can make changes under the hood.
Technique 2 – MySQL Workbench Database Synchronization
There is a great feature in MySQL Workbench that allows you to synchronize two databases.
It can automatically compare and create any change script. There are other third-party products that can do this as well (perhaps even more easily!).
Because MySQL Workbench is a free application developed by the MySQL Community, it may be the best alternative. However, always research a new tool before using it to make sure that it meets your own needs best.
There are a couple of things you need to keep in mind.
First, Workbench needs to create an EER Diagram to be able to compare the MySQL databases.
You can create the EER Diagram of your local schema and compare it with the remote MySQL database.
It will automatically display the differences. You can also change which way to synchronize – source to destination or destination to source.
Listed below are a few quick steps to make it easier for you:

- Open Workbench
- Click Database > Reverse Engineer
- Connect the MySQL Servers and choose the database
- When Reverse Engineering dialog disappears, go to “Arrange > Auto Layout” to have it organized
- Click Database > Synchronize With Any Source
- You may choose to save change script into a DB instead of executing it directly.
- Choose the other MySQL production Server and database
- Now you can see the differences between both databases and you can decide whether to synchronize them source to destination or destination to source.
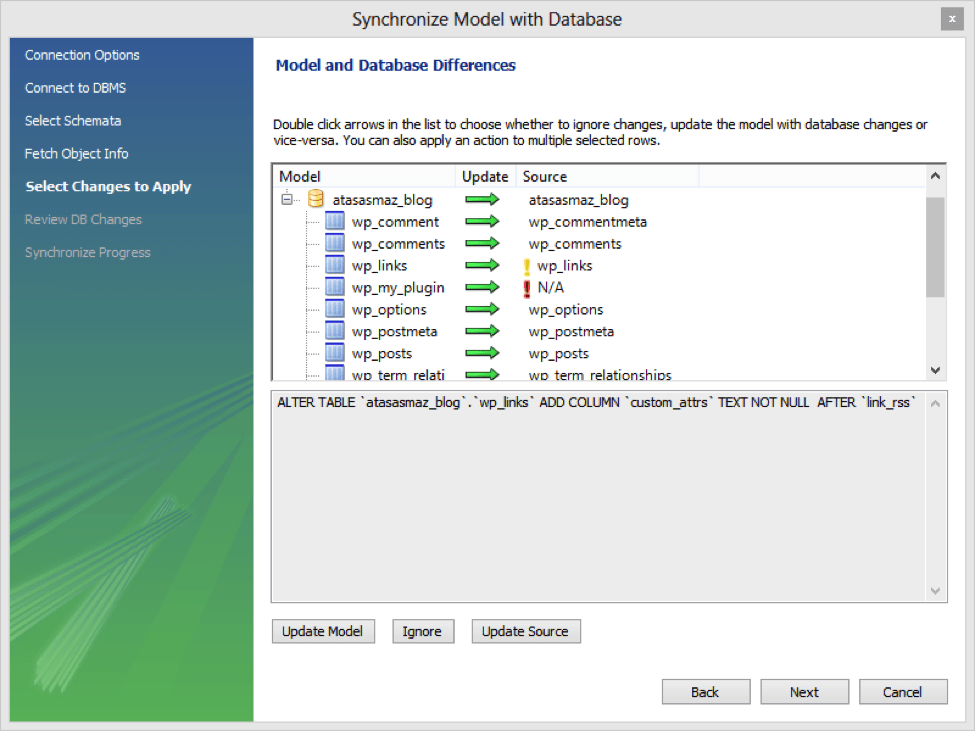
Keep in mind that the schema names should be the same for source and destination.
If they are not the same, generate the EER Diagram to Catalog Tree on the left, “Right Click > Edit Schema” and rename it.
Next, on the destination database selection window, Workbench will still ask whether or not you want to ignore the renaming. Ignore it; otherwise, it will rename the destination database, too.
It is possible to manage third-party software products like WordPress in different environments and synchronize the database changes with this second technique.
To learn more about our custom programming options, please contact us today!
FAQ – How to Manage Multiple Databases Across Testing, Development and Production Servers
How do you integrate multiple databases?
You can merge multiple databases into a single database to save time and space.
Create several smaller data tables, then use SQL queries or GoldenGate software for this task if needed (more on that later).
Once complete with one larger entity in place, there should be no need of ever referring back again – unless you want more than just stock quotes!
How do you manage multiple dev environments?
To promote a single design across multiple runtime environments, complete the following general steps:
Install Warehouse Builder components on all necessary computers;
Configure each separate machine with appropriate settings for its respective environment.
Can we create multiple databases?
There are two ways to organize database files.
The first means creating one physical file with multiple databases inside of it.
This helps when the number and size of your databases are high enough that you don’t want a large amount of additional supporting material taking up space on disk, but not too many so they become tedious for users who only have access through their own program (e.g., Excel).
Which software can handle multiple databases?
Navicat is a powerful database management and design application that supports multiple production databases.
It comes in the standalone program for Mac, Windows, or Linux to allow you to manage drivers like MySQL, Oracle database, MariaDB SQL Server & PostgreSQL easily with just one tool!
How do you set up a test to run multiple environments?
Testing against multiple environments is key to making sure your tests run quickly and accurately.
Create a JSON config file for each of the environments you want it to execute in, put these files into /etc on separate instances (elevate) not the same server, then use -e switch when running Storyplayer so it will choose which environment at random instead of performing all possible combinations with only 1 execution per node instance.
Why is there a separate development and production environment?
A development environment is like any other workstation in the office.
Development environments have their own set of files and folders that are only accessible by developers working on it, which helps to prevent them from accidentally messing with or deleting the production database-and also keeps sensitive information (e.g., passwords) away from people who shouldn’t have accessed it.
How many environments are required for software development?
There are four environments in which an application lives and breathes.
These locations can be segmented based on how they’re being used, just as you would have different states for your applications themselves.
What is the most popular SQL database?
As one of the most popular and widely used SQL databases, MySQL has been integral in many Web-Scale applications.
Some examples include Facebook and Uber which rely heavily on this database system for storing production data efficiently so that it can be accessed quickly by all users involved with those services – without having any issues or delays due to slow connectivity times from physical server locales away!
Is it better to have one database or multiple?
The best way to keep your database clean and organized is by using different databases for each client.
This means that if you want to modify a table in one of their databases, all other copies must be updated as well which can get difficult with large amounts of data-sets like those found on larger projects or companies might have (especially when they use third party software).
Grouping similar information into separate tables throughout the application helps avoid clutter while still allowing quick access without having to update multiple places at once – especially helpful during troubleshooting!
How do I merge two databases in SQL Server?
When merging databases that are using autogenerated (non-GUID) keys, you need to take several steps.
First, add a new key on the parent table and then import all data from both tables rename old file ID_old with its original name before renaming files for a newer version with a lower index number so they overwrite it as needed without having any issues during operation or when restoring backup afterward if necessary.


